
Какие способы вычисления среднего бывают?
Первым способом является вычисление уже упомянутого среднего арифметического, являющегося суммой всех значений, деленной на их количество.
Формула:
- x– среднее арифметическое;
- xn – конкретное значение;
- n – количество значений.
Плюсы:
- Хорошо работает при нормальном распределении значений в выборке;
- Легко вычислить;
- Интуитивно понятно.
Минусы:
- Не дает реального представления о распределении значений;
- Неустойчивая величина легко поддающаяся выбросам (как в случае с генеральным директором).
Вторым способом является вычисление моды, то есть наиболее часто встречающегося значения.
Формула:
- M– мода;
- x– нижняя граница интервала, который содержит моду;
- n – величина интервала;
- fm– частота (сколько раз в ряду встречается то или иное значение);
- fm-1 – частота интервала предшествующего модальному;
- fm+1 – частота интервала следующего за модальным.
Плюсы:
- Прекрасно подходит для получения представления об общественном мнении;
- Хорошо подходит для нечисловых данных (цвета сезона, хиты продаж, рейтинги);
- Проста для понимания.
Минусы:
- Моды может просто не быть (нет повторов);
- Мод может быть несколько (многомодальное распределение).
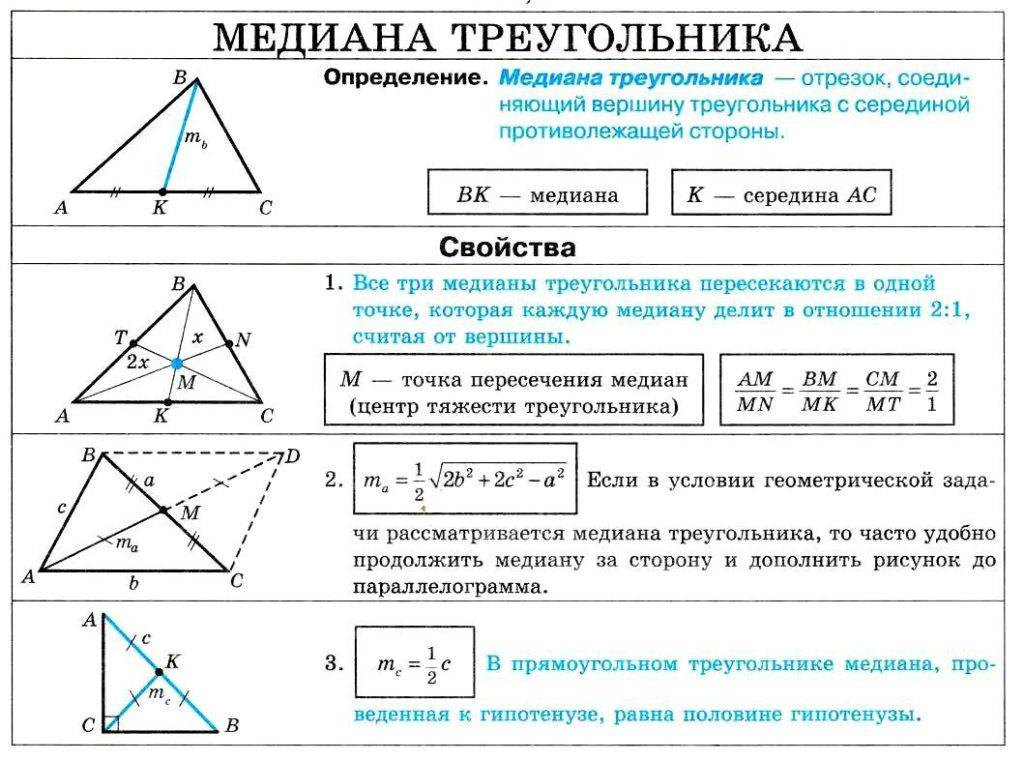
Третий способ — это вычисление медианы, то есть значения, которое делит упорядоченную выборку на две половины и находится между ними. А если такого значения нет, то за медиану принимается среднее арифметическое между границами половин выборки.
Формула:
- Me – медиана;
- x– нижняя граница интервала, который содержит медиану;
- h – величина интервала;
- f i – частота (сколько раз в ряду встречается то или иное значение);
- Sm-1 – сумма частот интервалов предшествующих медианному;
- fm – число значений в медианном интервале (его частота).
Плюсы:
- Дает самую реалистичную и репрезентативную оценку;
- Устойчива к выбросам.
Минусы:
Сложнее вычислить, так как перед вычислением выборку нужно упорядочить.
Мы рассмотрели основные методы нахождения среднего значения, называющиеся мерами центральной тенденции (на самом деле их больше, но это наиболее популярные).
А теперь давайте вернемся к нашему примеру и посчитаем все три варианта среднего при помощи специальных функций Excel:
- — функция для определения среднего арифметического;
- — функция моды (в более старых версиях Excel использовалась );
- — функция для поиска медианы.
И вот какие значения у нас получились:
В данном случае мода и медиана гораздо лучше характеризуют среднюю зарплату в компании.
Но что делать, когда в выборке не 10 значений, как в примере, а миллионы? В Excel это не посчитать, а вот в базе данных где хранятся ваши данные, без проблем.
Вычисляем среднее арифметическое на SQL
Тут все достаточно просто, так как в SQL предусмотрена специальная агрегатная функция .
И чтобы ее использовать достаточно написать вот такой запрос:
/* Здесь и далее salary - столбец с зарплатами, а employees - таблица сотрудников в нашей базе данных */ SELECT AVG(salary) AS 'Средняя зарплата' FROM employees
Вычисляем моду на SQL
В SQL нет отдельной функции для нахождения моды, но ее легко и быстро можно написать самостоятельно. Для этого нам необходимо узнать, какая из зарплат чаще всего повторяется и выбрать наиболее популярную.
Напишем запрос:
/* WITH TIES необходимо добавлять к TOP() если множество многомодально, то есть у множества несколько мод */ SELECT TOP(1) WITH TIES salary AS 'Мода зарплаты' FROM employees GROUP BY salary ORDER BY COUNT(*) DESC
Вычисляем медиану на SQL
Как и в случае с модой, в SQL нет встроенной функции для вычисления медианы, зато есть универсальная функция для вычисления процентилей .
Выглядит все это так:
/* В данном случае процентиль 0.5 и будет являться медианой */
SELECT TOP(1) PERCENTILE_CONT(0.5)
WITHIN GROUP (ORDER BY salary)
OVER() AS 'Медианная зарплата'
FROM employeesПодробнее о работе функции лучше почитать в справке Microsoft и .
Распределение вероятностей
Значения показателей в выборке могут быть более или менее вероятными. Для одних значений вероятность выше, для других ниже. То, как распределяются эти вероятности по разным значениям, и есть распределение. Так его описывает теория вероятностей и математическая статистика.
В науке о данных распределение можно считать не только для вероятности. Дата-сайентисты обобщают понятие как закон соответствия между одной и другой величиной. Классическое распределение вероятности — соответствие между значениями в выборке и вероятностью получить эти значения.
Равномерное распределение. Самый простой вариант — когда есть конкретные диапазоны значений со статичной вероятностью. График распределения состоит из прямых, горизонтальных и вертикальных линий. А если переменная категориальная, то есть может принимать несколько значений, ее изображают как несколько равномерных распределений.
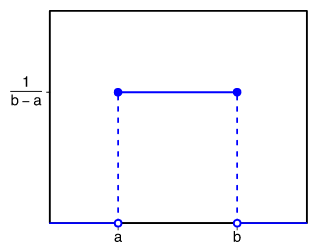 Простейший график равномерного распределения. Источник
Простейший график равномерного распределения. Источник
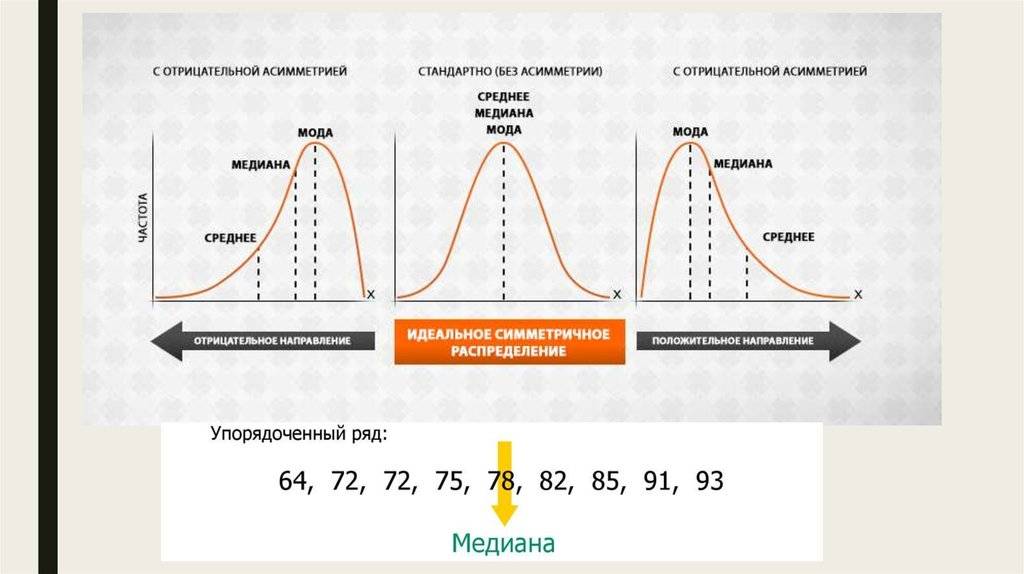
Нормальное распределение. Оно встречается чаще всего и в Data Science, и вообще в мире. Распределение на графике выглядит как холм, который называют колоколом Гаусса или гауссианой.
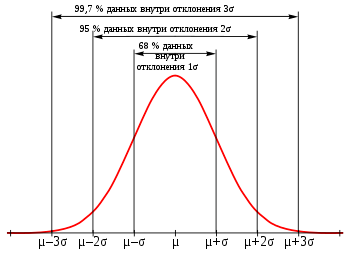 Гауссиана нормального распределения. Источник
Гауссиана нормального распределения. Источник
Колокол показывает: вероятность получить «среднее» значение больше всего. Чем больше отклонение от среднего, тем ниже вероятность. Для самых низких или высоких значений вероятность особенно низкая. Колокол может быть сдвинут влево или вправо относительно среднего — по медиане.
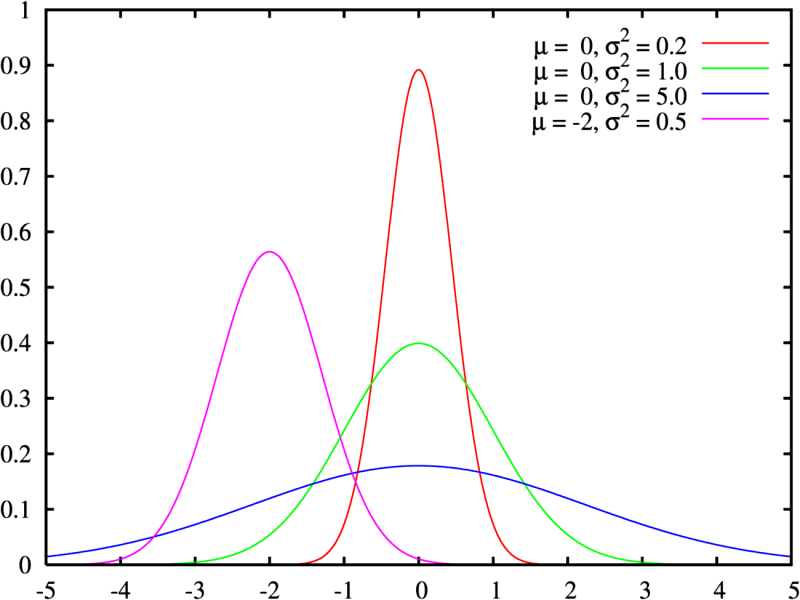 Так может сдвигаться гауссиана. Источник
Так может сдвигаться гауссиана. Источник
Считается, что нормально распределенными оказываются практически все величины, где результат зависит от огромного количества мелких факторов. Оно самое известное и часто встречающееся в природе, поэтому его и назвали нормальным.
Распределение Пуассона. В некоторых случаях очень похоже на нормальное. Распределение используют для анализа количества событий за определенный промежуток времени. События должны быть не связаны друг с другом. У распределения Пуассона есть дополнительный показатель интенсивности, который влияет на форму графика: чем выше, тем больше похоже на гауссиану.
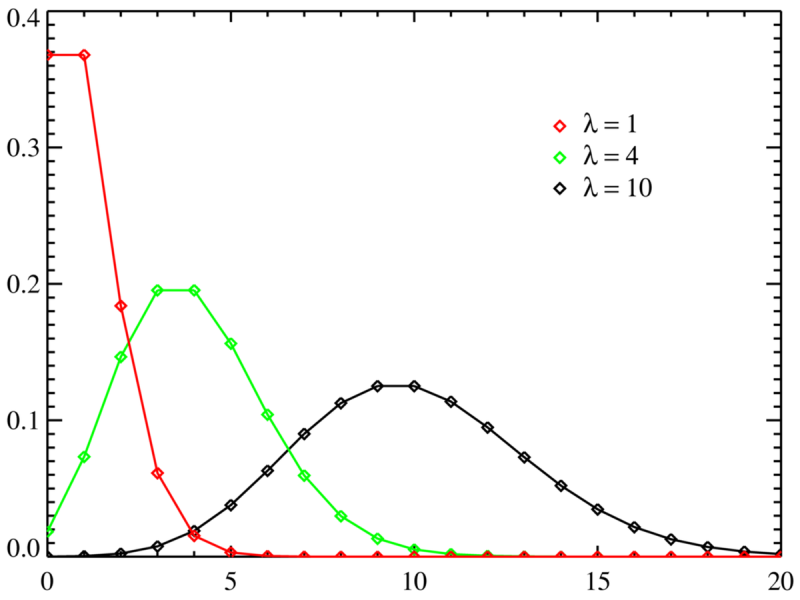 Графики распределения Пуассона с разным показателем интенсивности. Источник
Графики распределения Пуассона с разным показателем интенсивности. Источник
Бимодальное распределение
Если вы работаете со средними, остерегайтесь бимодального распределения. Во многих наборах данных — биологических, физических, социальных — у распределения может быть два или больше пиков. 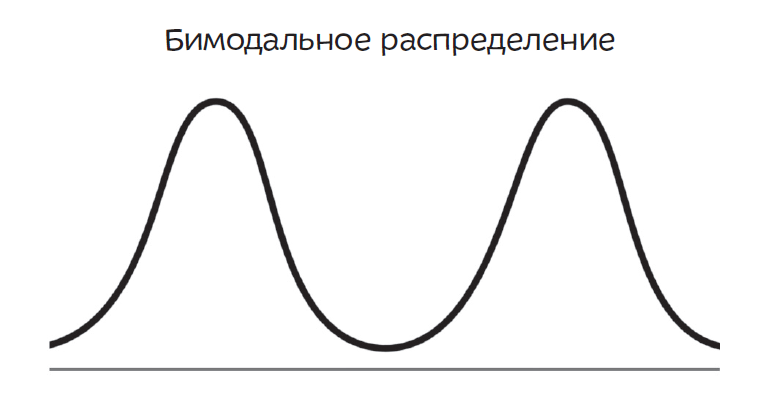
Например, подобный график может отображать сумму, потраченную на обеды в неделю (ось X), и количество людей, потративших такую сумму (ось Y). Представьте, что вы изучали две группы людей: детей (левый горб) — они покупают школьные обеды — и руководителей компаний (правый горб) — они ходят в дорогие рестораны.






Среднее арифметическое и медиана в данном случае — это числа где-то между этими двумя горбами, и они ничего не скажут о том, что происходит на самом деле, — ведь во многих случаях среднее арифметическое и медиана отражают ту сумму, которую никто не тратит. Подобный график говорит лишь о том, что в вашем примере имеет место неоднородность — вы сравниваете яблоки с апельсинами. В таком случае лучше сразу сказать, что вы имеете дело с бимодальным распределением, и сообщить о двух модах. А еще лучше разделить группу на две подгруппы и собрать статистические данные для каждой.
Примеры использования медианы и среднего арифметического
Медиана:
Медиана является средним значением ряда данных, отсортированного по порядку. Она обладает следующим свойством: половина значений меньше медианы, а другая половина – больше.
Рассмотрим пример использования медианы на практике. Представим, что у нас есть группа из 7 учеников, их возрасты составляют: 10, 11, 12, 12, 13, 14, 16. Для определения медианы мы сначала упорядочим данные в порядке возрастания: 10, 11, 12, 12, 13, 14, 16. Затем найдем середину ряда: (12+13)/2 = 12.5. Итак, медиана составляет 12.5 лет.
Одним из преимуществ использования медианы является то, что она более устойчива к выбросам (необычным значениям) в данных. Например, если в нашем ряде данных по возрасту появится ученик возрастом 80 лет, медиана по-прежнему будет равна 12.5 лет, тогда как среднее арифметическое значительно увеличится. Это делает медиану полезным инструментом для анализа данных, особенно в случаях, когда выбросы могут искажать общую картину.
Среднее арифметическое:
Среднее арифметическое – это простая мера центральной тенденции, которая вычисляется путем деления суммы всех значений на количество значений в ряде.
Рассмотрим пример использования среднего арифметического. Представим, что у нас есть результаты 5 учеников в математическом тесте: 85, 90, 92, 88, 95. Чтобы найти среднее арифметическое, мы складываем все значения и делим их на количество значений: (85+90+92+88+95)/5 = 90. Таким образом, среднее арифметическое равно 90.
Среднее арифметическое широко используется в статистике и науке для получения общего представления о данных. Однако среднее арифметическое может быть чувствительным к выбросам в данных. Например, если в нашем примере один из учеников получит 25 баллов, среднее арифметическое значительно снизится, и оно уже не отражает общую картину успеха группы.
Мода и медиана
Модой называют элемент, который встречается в выборке чаще других.
Рассмотрим следующую выборку: шестеро спортсменов, а также время в секундах за которое они пробегают 100 метров

Элемент 14 встречается в выборке чаще других, поэтому элемент 14 назовем модой.
Рассмотрим еще одну выборку. Тех же спортсменов, а также смартфоны, которые им принадлежат

Элемент iphone встречается в выборке чаще других, значит элемент iphone является модой. Говоря простым языком, носить iphone модно.
Конечно элементы выборки в этот раз выражены не числами, а другими объектами (смартфонами), но для общего представления о моде этот пример вполне приемлем.
Рассмотрим следующую выборку: семеро спортсменов, а также их рост в сантиметрах:

Упорядочим данные в таблице так, чтобы рост спортсменов шел по возрастанию. Другими словами, построим спортсменов по росту:

Выпишем рост спортсменов отдельно:
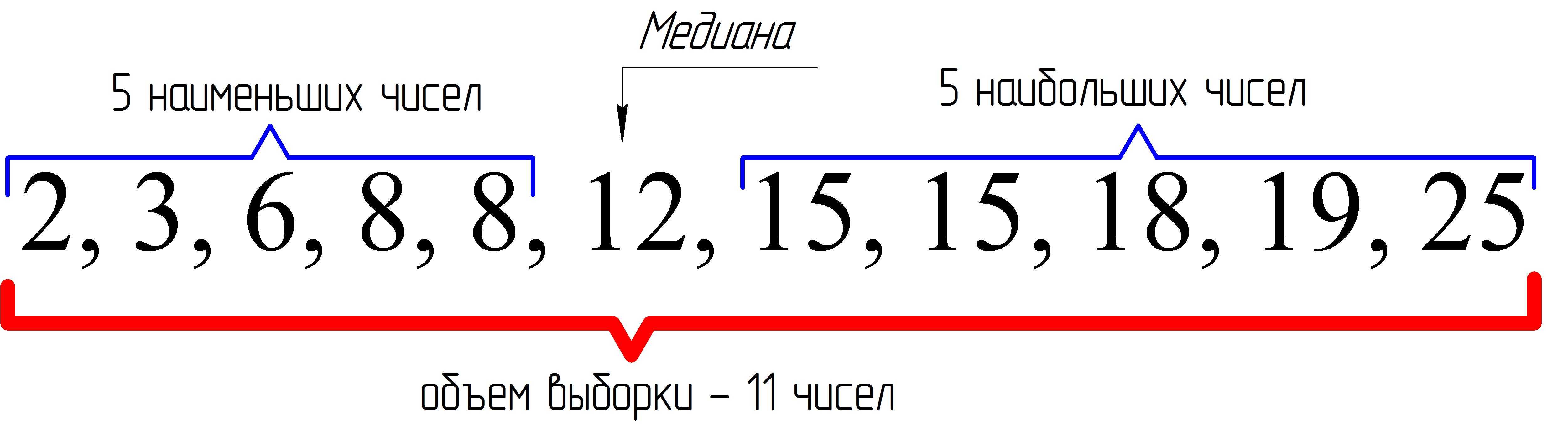
180, 182, 183, 184, 185, 188, 190
В получившейся выборке 7 элементов. Посередине этой выборки располагается элемент 184. Слева и справа от него по три элемента. Такой элемент как 184 называют медианой упорядоченной выборки.
Медианой упорядоченной выборки называют элемент, располагающийся посередине.
Отметим, что данное определение справедливо в случае, если количество элементов упорядоченной выборки является нечётным.
В рассмотренном выше примере, количество элементов упорядоченной выборки было нечётным. Это позволило нам быстро указать медиану
Но возможны случаи, когда количество элементов выборки чётно.
К примеру, рассмотрим выборку в которой не семеро спортсменов, а шестеро:

Построим этих шестерых спортсменов по росту:

Выпишем рост спортсменов отдельно:
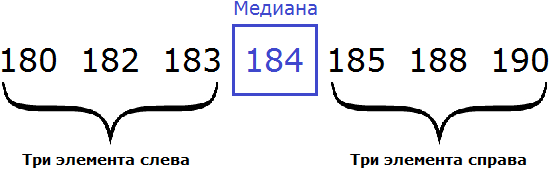
180, 182, 184, 186, 188, 190
В данной выборке не получается указать элемент, который находился бы посередине. Если указать элемент 184 как медиану, то слева от этого элемента будут располагаться два элемента, а справа — три. Если как медиану указать элемент 186, то слева от этого элемента будут располагаться три элемента, а справа — два.
В таких случаях для определения медианы выборки, нужно взять два элемента выборки, находящихся посередине и найти их среднее арифметическое. Полученный результат будет являться медианой.
Вернемся к нашим спортсменам. В упорядоченной выборке 180, 182, 184, 186, 188, 190 посередине располагаются элементы 184 и 186

Найдем среднее арифметическое элементов 184 и 186
Элемент 185 является медианой выборки, несмотря на то, что этот элемент не является членом исходной и упорядоченной выборки. Спортсмена с ростом 185 нет среди остальных спортсменов. Рост в 185 см используется в данном случае для статистики, чтобы можно было сказать о том, что срединный рост спортсменов составляет 185 см.









Поэтому более точное определение медианы зависит от количества элементов в выборке.
Если количество элементов упорядоченной выборки нечётно, то медианой выборки называют элемент, располагающийся посередине.
Если количество элементов упорядоченной выборки чётно, то медианой выборки называют среднее арифметическое двух чисел, располагающихся посередине этой выборки.
Медиана и среднее арифметическое по сути являются «близкими родственниками», поскольку и то и другое используют для определения среднего значения. Например, для предыдущей упорядоченной выборки 180, 182, 184, 186, 188, 190 мы определили медиану, равную 185. Этот же результат можно получить путем определения среднего арифметического элементов 180, 182, 184, 186, 188, 190
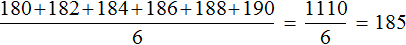
Но медиана в некоторых случаях отражает более реальную ситуацию. Например, рассмотрим следующий пример:
Было подсчитано количество имеющихся очков у каждого спортсмена. В результате получилась следующая выборка:
0, 1, 1, 1, 2, 1, 2, 3, 5, 4, 5, 0, 1, 6, 1
Определим среднее арифметическое для данной выборки — получим значение 2,2
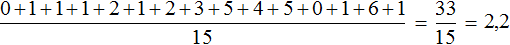
По данному значению можно сказать, что в среднем у спортсменов 2,2 очка
Теперь определим медиану для этой же выборки. Упорядочим элементы выборки и укажем элемент, находящийся посередине:
0, 0, 1, 1, 1, 1, 1, 1, 2, 2, 3, 4, 5, 5, 6
В данном примере медиана лучше отражает реальную ситуацию, поскольку половина спортсменов имеет не более одного очка.
Источники данных и статистические методы для расчета медианы и среднего арифметического
Для расчета медианы и среднего арифметического используются различные источники данных и статистические методы. В зависимости от типа данных и их распределения выбираются соответствующие подходы.
Источники данных для расчета медианы и среднего арифметического могут быть разнообразными. Одним из наиболее часто используемых источников данных являются выборки из статистических исследований. В таких выборках каждое наблюдение представляет собой отдельное значение из исследуемой генеральной совокупности. Для расчета медианы и среднего арифметического по выборке применяются соответствующие формулы и алгоритмы.
Статистические методы для расчета медианы и среднего арифметического также могут различаться в зависимости от типа данных. Например, для непрерывных переменных часто используется метод интерполяции. При этом значения переменных располагаются на оси координат, и медиана и среднее арифметическое находятся в точке пересечения соответствующих отрезков графика.
Для дискретных переменных существуют различные методы расчета медианы и среднего арифметического. Например, для дискретных переменных с равными интервалами между значениями можно использовать формулу расчета среднего арифметического. Для переменных с неравными интервалами между значениями можно применять методы, основанные на взвешивании значений переменных.
В общем случае, для расчета медианы и среднего арифметического могут использоваться как простые статистические методы, так и более сложные аналитические подходы. Выбор конкретного метода зависит от характера данных, целей исследования и предпочтений исследователя.
- Медиана — это значение, которое располагается посередине в упорядоченном наборе чисел. Она не зависит от выбросов и позволяет оценить типичное значение в выборке.
- Среднее арифметическое — это сумма всех значений, деленная на их количество. Оно учитывает все значения в выборке и может быть сильно искажено наличием выбросов.
Выбор между медианой и средним зависит от ситуации и целей анализа данных.
- Если выборка содержит выбросы или аномальные значения, медиана может быть более предпочтительной метрикой, так как она не будет сильно искажена этими значениями.
- Среднее арифметическое может быть полезно, если выборка состоит из набора схожих значений и не содержит выбросов.
Использование обеих метрик вместе может помочь получить более полное представление о данных и их распределении.
Что такое медиана и среднее значение?
Медиана и среднее значение — это два способа измерить центральную тенденцию в наборе данных. Среднее значение — это сумма всех значений, разделенная на количество значений в наборе. Медиана — это среднее значение двух средних значений, если число значений в наборе четное, или это среднее значение нижнего и верхнего квартилей, если число значений в наборе нечетное.
Среднее значение является наиболее распространенным способом оценки центральной тенденции, но медиана может быть более подходящей мерой, если в данных есть выбросы. Выбросы могут исказить среднее значение, тогда как медиана останется более устойчивой.
Кроме того, в некоторых случаях с использованием медианы может быть легче понять распределение данных. Например, если есть много значений, близких к медиане, и несколько значений, далеких от нее, можно сделать вывод, что распределение данных смещено.
Использование медианы или среднего значения зависит от того, какие данные анализируются и какую информацию о них необходимо извлечь
Важно помнить, что медиана и среднее значение — это лишь два из множества способов описания данных, и выбор определенного метода зависит от цели анализа данных
В каких случаях использовать среднее арифметическое
Среднее арифметическое рекомендуется использовать, когда данные представляют собой числовой набор, и требуется получить одно число, которое наиболее хорошо характеризует этот набор. Оно особенно полезно, когда набор данных имеет нормальное распределение и не содержит выбросов.
Среднее арифметическое обладает рядом преимуществ. Во-первых, оно достаточно просто вычисляется, добавляя все значения и деля их на количество значений. Во-вторых, оно устойчиво к малым изменениям в данных и может быть использовано для сравнения различных наборов данных. В-третьих, оно хорошо интерпретируется и понятно для большинства людей.
Среднее арифметическое также используется в прогнозировании и планировании. Например, предприятие может использовать его для расчета средней выручки или средних издержек. Также оно может быть полезным при анализе финансовых данных, оценке риска или определении средней продолжительности жизни.
Однако стоит помнить, что среднее арифметическое может быть чувствительным к выбросам. Если набор данных содержит несколько значений, которые сильно отклоняются от остальных, среднее арифметическое может быть не представительным для общей тенденции данных. В таких случаях более уместно использовать медиану.
Выборка. Объем. Размах
Что такое выборка? Если говорить простым языком, то это отобранная нами информация для исследования. Например, мы можем сформировать следующую выборку — суммы денег, потраченных в каждый из шести дней. Давайте нарисуем таблицу в которую занесем расходы за шесть дней

Выборка состоит из n-элементов. Вместо переменной n может стоять любое число. У нас имеется шесть элементов, поэтому переменная n равна 6
n = 6
Элементы выборки обозначаются с помощью переменных с индексами . Последний элемент является шестым элементом выборки, поэтому вместо n будет стоять число 6.

Обозначим элементы нашей выборки через переменные
Количество элементов выборки называют объемом выборки. В нашем случае объем равен шести.
Размахом выборки называют разницу между самым большим и маленьким элементом выборки.
В нашем случае, самым большим элементом выборки является элемент 250, а самым маленьким — элемент 150. Разница между ними равна 100
Comparison Table
| Parameters of Comparison | Mean | Median |
|---|---|---|
| Definition | Mean is the average of a given set of data. | The median is the middle or center of the data. |
| Formula | m = sum of terms/number of terms | M = (n+1)/2, term for an odd data set. M = [n/2 term + (n/2 +1) term ] / 2 , for even data set. |
| Uses | In sports, to calculate overall performances of a student or an employee, etc. | In daily life problems like grouping data, buying a property, etc. |
| Skewness | The mean is susceptible to skewed data. | The median is not much affected by Skewed Data. |
| Central Tendency | Mean is a well-known measure for a central tendency. | Mean is affected by outliers due to which median is used and is a much better option for a central tendency. |
Овер- и андерсемплинг: когда размеры не совпадают
Два вида семплирования, которые стоит обсудить подробнее. Понятие используют в задачах классификации, когда нужно проанализировать данные и разделить на классы. Чаще всего этим занимаются специалисты по машинному обучению. Проблема начинается, когда аналитическая модель получает классы данных разного размера. Один класс больше (мажоритарный), другой меньше (миноритарный).









Например, два класса — пользователи моложе и старше 30 лет. В первом классе 2000 человек, в во втором всего 200. Разница в десять раз дает заметный перекос.
Если оставить все как есть, аналитическая модель может ошибиться. Например, в будущем начать относить все новые данные к мажоритарному классу. Поэтому классы балансируют: для этого как раз нужны оверсемплинг и андерсемплинг.
- Оверсемплинг — способ, когда данные в минориторном классе клонируют, чтобы их стало больше. Причем клонируют так, чтобы не нарушить изначальные соотношения значений и распределение.
- Андерсемплинг — способ, когда мажоритарный класс уменьшают. Проще всего убрать случайные значения, но чаще уменьшение опять же делается так, чтобы не нарушить соотношения.
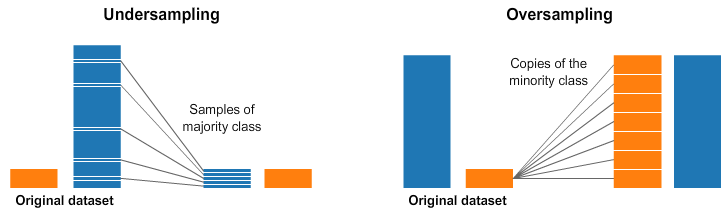 Андерсемплинг и оверсемплинг. Источник
Андерсемплинг и оверсемплинг. Источник
При выборе метода нужно помнить о цене ошибки. Обычно она перекошена в сторону конкретного класса. Ошибочно причислить неплательщика к группе «можно дать кредит» более затратно для компании, чем причислить благополучного плательщика к группе «нельзя дать кредит». В таких случаях выбирают методы, которые фильтруют одну группу жестче, чем другую.
Как правильно использовать медиану в статистике
Для правильного использования медианы в статистике, следует учитывать несколько важных моментов:
1. Подходящий тип данных:
Медиана можно использовать для оценки центральной тенденции только для количественных данных. Для категориальных данных медиана не имеет смысла.
2. Непрерывные данные:
Медиана считается для непрерывных данных. Если у вас есть дискретные данные, нужно использовать другие методы, например, моду или среднее значение.
3. Определение медианы:
Медиана находится путем упорядочивания данных по возрастанию или убыванию и выбора значения, находящегося посередине. Если в выборке нечетное количество элементов, медиана — это серединное значение. А если количество элементов четное, медиана — это среднее арифметическое двух соседних значений.
4. Игнорирование выбросов:
Одним из главных преимуществ медианы является то, что она нечувствительна к выбросам. Это означает, что медиана дает более устойчивую оценку в случае наличия необычных значений или аномалий в данных.
5. Понимание интерпретации:
Правильное использование медианы также включает понимание ее интерпретации. Медиана является порядковой статистикой, поэтому ее значение может быть представлено как «меньше или равно» значению медианы. Например, если медиана выборки равна 10, это означает, что 50% значений меньше или равны 10.
Отличия определений
Формулировка и определение
Медиана делит последовательность пополам, причем 1 часть состоит из элементов, меньших этой величины, а 2 часть состоит из больших чисел. Среднее арифметическое — это сумма всех элементов, деленная на их количество.
Данные в некоторых случаях совпадают, однако чаще всего они имеют разные значения.
Точность вычислений
Среднее арифметическое дает неточный итог подведения статистики, особенно если данных слишком много. Некоторые статисты заменяют его модой — элемент, который чаще всего встречается в последовательности. В частных случаях необходимо использовать среднее геометрическое, так как арифметическое дает неточный результат. Оценить эффективность величины можно только после применения его на практике, изучения всех значений последовательности и вычисления других статистических характеристик.
Медиана является более точной величиной, чем другое множество.
Однако для эффективной статистики необходимо учитывать сразу несколько показателей.
Применение
Для большинства обывателей медиана — это не статистическая величина, а математическая. Она чаще применяется в геометрических задачах на треугольники, как отрезок или луч. Многие даже не знают, что данное определение применимо к статистике. Его используют только при специализированных отчетах, для подведения итога. В устных докладах переменную не озвучивают, однако в документации ее необходимо описывать.
Среднее арифметическое также применяется в математике, однако в статистике оно известно не меньше. Его часто используют в СМИ, политике и экономике. Эта переменная изучается на начальной стадии обучения статистике.
Для большинства обывателей среднее арифметическое — более понятная величина, несмотря на то, что она неточна во многих случаях.
